You Only Sample Once: Taming One-Step Text-To-Image Synthesis by Self-Cooperative Diffusion GANs
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)

目录
0. 摘要
2. 相关工作
3. 背景
4. 方法:自协同扩散 GANs
4.1 重新审视 Diffusion GANs
4.2 我们的设计
5. 朝向一步文本到图像合成
5.1 使用预训练模型进行训练
5.2 固定噪声调度器
6. 实验
0. 摘要
我们介绍了 YOSO,一种新型的生成模型,旨在实现快速、可扩展和高保真度的一步图像合成。这是通过将扩散过程与 GAN 集成实现的。具体来说,我们通过去噪生成器本身平滑分布,执行自协同(self-cooperative)学习。我们展示了我们的方法可以作为一个从头开始进行训练的一步生成模型,并具有竞争性能。此外,我们展示了我们的方法可以扩展到微调预训练的文本到图像扩散,用于高质量的一步文本到图像合成,即使进行了 LoRA 微调。特别地,我们提供了第一个扩散 transformer,可以在 512 分辨率上进行训练并生成图像,具有无需明确训练即可适应 1024 分辨率的能力。

2. 相关工作
少量步文本到图像生成。最近,已经开发了几种用于几步文本到图像生成的工作。
LCM [30] 基于一致性蒸馏(consistency distillation) [49],将其调整为稳定扩散(SD),并使图像在 4 步中具有可接受的质量。然而,减少采样步骤导致生成质量较差。
InstaFlow [27] 基于矫正流(Rectified Flows) [26, 25],将其调整为稳定扩散,促进了仅一步生成文本到图像。尽管如此,生成图像的保真度仍然较低。此外,由于模型在固定数据噪声配对上的训练,失去了支持可变数据噪声组合的灵活性,这对于像图像修改或可以提高生成图像质量的迭代多步采样任务是有害的。
最近,探索了将 DM 和 GAN 结合用于一步文本到图像生成。UFOGen 将 DDGANs [52] 和 SSIDMs [57] 扩展到稳定扩散,通过将重建损失的计算从损坏样本改为清洁(clean)样本来进行修改。然而,它仍然使用损坏样本进行对抗匹配。
ADD [44] 提出了基于稳定扩散的一步文本到图像生成。它遵循早期研究,使用预训练的图像编码器 DINOv2 [35] 作为鉴别器的骨干来加速训练。然而,鉴别器设计将训练从潜在空间移动到像素空间,这大大增加了计算需求。此外,它们直接在清洁的真实数据上执行对抗匹配,增加了训练的挑战。这需要更好但昂贵的鉴别器设计和昂贵的 R1 正则化来稳定训练。
相比之下,我们通过用自生成数据替换真实数据来进行对抗训练,以平滑地实现真实数据。此外,与 UFOGen 和 ADD 相比,我们的方法可以从头开始训练以执行一步生成,这是他们没有展示的。此外,我们将我们的方法不仅扩展到 Stable Diffusion,还扩展到基于扩散 Transformer [37] 的 PixArt-α [6]。这证明了我们提出的 YOSO 的广泛应用。
(2023,训练分解,高效 DiT,高信息数据集)PIXART-α:用于逼真文本到图像合成的扩散Transformer的快速训练
3. 背景
(2022|ICLR,扩散 GAN,少量步扩散,对抗散度,非饱和 GAN)用去噪扩散 GAN 解决生成学习难题
(2024,EBGAN,扩散,变分近似)通过扩散过程改进基于能量的对抗模型
扩散-GAN 混合模型。扩散模型中的一个问题是,当去噪步长较大时,真实的 q(x_(t−1) | xt) 不再是一个高斯分布。因此,Diffusion GANs [52] 提议不再使用参数化的高斯分布来最小化负 ELBO,而是提出最小化模型 pθ(x′_(t−1) | xt) 和 q(x_(t−1) | xt) 之间的对抗差异:
![]()
![]()
其中,pθ(x0|xt) 是由 GAN 生成器强加的。 基于 GAN 的 pθ(x′_(t−1) | xt) 公式的能力,使得更大的去噪步长(即 4 步)成为可能,相比之下高斯分布要小得多。
4. 方法:自协同扩散 GANs
4.1 重新审视 Diffusion GANs
扩散-GAN 混合模型被设计用于训练大去噪步长。然而,一个关键问题是它们在损坏的数据分布上匹配生成器分布
![]()
这种公式只间接学习 pθ(x0|xt) 且 pθ(x0) =
![]()
这是用于一步生成的分布,使得学习过程不够有效。
4.2 我们的设计
为了实现更有效的一步生成学习,我们建议直接构建在干净数据上的学习目标。我们首先按以下方式构建干净数据的序列分布:
![]()
![]()
其中 q(x0) 是数据分布,而 Gθ 是去噪生成器,用于预测干净样本。如果网络 ϵθ 被参数化以预测噪声,我们有
![]()
给定构建的分布,我们可以如下制定优化目标:

优化目标是通过对抗散度和 KL 散度的组合构建的。具体而言,对抗散度侧重于在分布级别上匹配,确保生成质量,而 KL 散度侧重于在点级别上匹配,确保模式覆盖。
然而,直接学习在干净数据分布上的对抗散度与 GAN 训练的挑战类似,这是困难的。为了解决这些挑战,之前的 Diffusion GAN [52, 57] 已经转向学习在损坏数据分布上的对抗散度。不幸的是,正如之前分析的那样,这种方法无法直接匹配 pθ(x0),从而削弱了一步生成的效果。此外,它还迫使鉴别器适应不同水平的噪声,导致其能力受限。
回想一下,p^(t)_θ (x) 被定义为
![]()
分布的质量有两个关键因素:1)可训练生成器 Gθ 的能力;2)由 xt 给出的信息。
因此,假设给定生成器 Gθ 固定,如果增加 xt 中的信息量,可以得到更好的分布。换句话说,p^(t−1)_θ (x) 很可能优于 p^(t)_θ (x)。 受到协同方法(cooperative approach) [53–55, 11] 的启发,该方法使用模型分布的马尔可夫链蒙特卡洛(MCMC)修订版本来学习生成器,我们建议使用 p^(t−1)_θ (x) 作为学习 p^(t)_θ (x) 的地面真实,构建以下训练目标:
![]()
其中 sg[·] 表示停梯度(stop-gradient)操作。这个训练目标可以看作是一种自协同方法,因为来自 p^(t−1)_θ (x) 的 ‘修订’ 样本和来自 p^(t)_θ (x) 的样本由相同的网络 Gθ 生成。请注意,我们仅在平滑学习目标时用数据分布替换 p^(t−1)_θ (x) 作为对抗散度,因为最近的研究 [32] 发现用真实数据和修订数据混合学习生成器是有益的。
在上述分布匹配目标中,我们应用了非饱和 GAN 目标来最小化边际分布的对抗散度。点匹配的 KL 散度可以通过 L2 损失进行优化。因此,可处理的训练目标如下所示:
![]()
其中 Dϕ 是鉴别器网络。我们发现自协同方法与一致性模型 [49] 相关联。然而,一致性模型将 x_(t−1) 视为 xt 的近似 ODE 解以执行点对点匹配(像素级别)。相比之下,我们提出的目标在边际分布级别上匹配 p^(t)_θ (x) 和 p^(t−1)_θ (x),这避免了与去噪步长相关的 ODE 近似误差。 为了进一步确保所提出模型的模式覆盖,我们可以将一致性损失添加到我们的目标中作为正则化,构建我们的最终训练目标:

其中 λcon(t) 是一个依赖于时间的超参数。
5. 朝向一步文本到图像合成
由于从头训练文本到图像模型的训练成本相当昂贵,我们建议使用预训练的文本到图像扩散模型作为自协同扩散 GAN 的初始化。在本节中,我们介绍了几种基于预训练 DM 开发生成模型的基本设计,从而实现基于预训练 DM 的一步文本到图像合成。
5.1 使用预训练模型进行训练
潜在感知损失。先前的研究 [15, 14, 49] 已经确认了感知损失在各个领域的有效性。值得注意的是,最近的研究 [27, 49] 发现,LPIPS 损失 [62] 对于获得具有高样本质量的少量步扩散模型至关重要。然而,值得注意的缺点是,LPIPS 损失是在数据空间中计算的,这是昂贵的。相比之下,流行的潜在扩散模型在潜在空间中运行,以减少计算需求。因此,在训练潜在扩散模型时使用 LPIPS损失是非常昂贵的,因为它不仅需要在数据空间中计算 LPIPS 损失,还需要额外的解码操作。
意识到预训练的稳定扩散可以作为有效的特征提取器 [56],我们建议使用预训练的稳定扩散执行潜在感知损失。然而,稳定扩散是一个 UNet,其最终层预测与数据相同维度的 epsilon。因此,我们建议使用 UNet 的瓶颈层来计算:
![]()
其中 z 是由 VAE 编码的潜在图像,ctext 是文本特征。我们注意到通过稳定扩散计算潜在感知损失的好处不仅在于计算效率,而且在于融合了文本特征,这在文本到图像任务中至关重要。
潜在鉴别器。在大规模数据集上为文本到图像任务训练 GAN 面临着严重挑战。具体来说,与无条件生成不同,用于文本到图像任务的鉴别器应基于图像质量和文本对齐进行验证。这个挑战在训练的初始阶段更加明显。为了解决这个问题,之前的纯粹的文本到图像 GAN [18] 提出了复杂的学习目标,并且需要昂贵的训练成本。
已经证明,使用预训练网络作为鉴别器可以使 GAN 的学习受益。如上所述,预训练的文本到图像扩散已经学习了代表性特征。因此,我们建议应用预训练的稳定扩散来构建潜在鉴别器。与潜在感知损失类似,我们只使用一半的 UNet 作为鉴别器,后面跟着一个简单的预测头。所提出策略的优势有两方面:1)我们使用信息丰富的预训练网络作为初始化;2)鉴别器定义在潜在空间中,具有计算效率。与以前在数据空间中定义鉴别器并需要解码潜在图像并从解码器反向的、具有昂贵的计算成本的方法不同,通过应用潜在鉴别器,我们观察到训练过程更加稳定,收敛速度更快。请注意,在我们的方法中不需要昂贵的 R1 正则化。
5.2 固定噪声调度器
扩散模型中的一个常见问题是最终的损坏样本不是纯噪声。例如,稳定扩散使用的噪声计划使得终端信噪比(terminal SNR)远未达到零。最终时间步的损坏样本如下:
![]()
其中,终端 SNR 是
![]()
有效地在训练和推断之间创建了一个差距。 先前的工作 [24] 只观察到这样的问题使得扩散模型无法产生纯黑色或白色的图像,这并没有严重损害样本质量。然而,我们发现这个问题在一步生成中会导致严重的问题。如图 2 所示,如果我们直接从标准高斯分布中采样噪声,在一步生成中会出现明显的伪影。原因可能是在多步生成中,可以逐渐修复这个差距,而一步生成更直接地反映了这个差距。为了解决这个问题,我们提供了两种简单而有效的解决方案。

信息先验初始化(Informative Prior Initialization,IPI)。非零终端 SNR 问题类似于 VAE 中的先验空洞(prior hole)问题 [22, 3, 21]。因此,我们可以使用信息先验而不是非信息先验来有效解决这个问题。为简单起见,我们采用可学习的高斯分布 N(μ, σ^2·I),其最优形式如下:
![]()
其中 E_x x 和 Std(x) 可以通过有限样本有效地估计,而 ϵ′ 遵循标准高斯分布。所提出的信息先验初始化有效地解决了一步生成中的 “先验空洞问题”。如图 2 所示,一步生成中的伪影立即消除。我们注意到,这种性能是通过最小的调整实现的,从而使得通过 LoRa 微调开发一步文本到图像生成的可能性成为可能。

快速适应 V 预测(V-prediction)和零终端(Zero Terminal) SNR。信息先验初始化并不是一个完美的解决方案,当终端 SNR 非常低时,它会受到数值不稳定性的影响。如图 3 所示,我们对 PixArt-α [6] 进行微调,其终端 SNR 为 4e-5,并引入了技术和 ϵ-预测,但在一步生成中失败了。正如在 [24] 中讨论的那样,解决方案应该是 v-预测 [42] 和零终端 SNR 的组合。然而,我们发现直接切换到 v-预测和零终端 SNR 是计算量很大的,需要大量的额外迭代。这在解决具有有限计算资源的大规模文本到图像问题中是不可接受的。为了解决这个问题,我们提出了一个适应阶段,将预训练的扩散模型微调到 v-预测和零终端 SNR。
适应阶段-I 切换到 v-预测:
![]()
![]()
其中 θ 表示我们要获取的 v-预测模型的参数,ϕ 表示带有 ϵ-预测的冻结预训练模型的参数。
适应阶段-II 切换到零终端 SNR:
![]()
请注意,在适应阶段-II 中,我们将噪声调度器更改为零终端 SNR。但对于教师模型,我们保持噪声调度器不变。这种方法避免了零终端 SNR 的 ϵ-预测的数值不稳定性问题。我们注意到,零终端 SNR 在每个时间步上具有比原始调度更低的 SNR,因此,通过从教师中蒸馏,损失构成了一个有效的目标来构建零终端 SNR 学生。
我们注意到,这种适应阶段收敛迅速,通常只需要1000次迭代训练。这使得可以从预训练的 ϵ-预测模型快速适应到 v-预测和零终端SNR,从而全面缓解了噪声调度中的非零终端 SNR 问题。
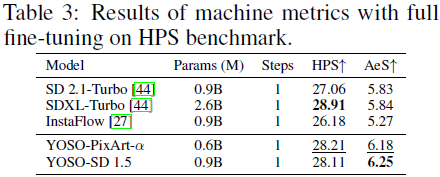
6. 实验

注:从实验结果看,验证了 Diffusion GANs [52] 中的说法(直接从复杂分布单步生成样本会影响性能:YOSO 3.82 vs DDGANs 3.75),但是 YOSO 的单步生成实现了高效生成(0.05s vs 0.21s)。因此,在应用时,需要根据实际情况进行权衡。
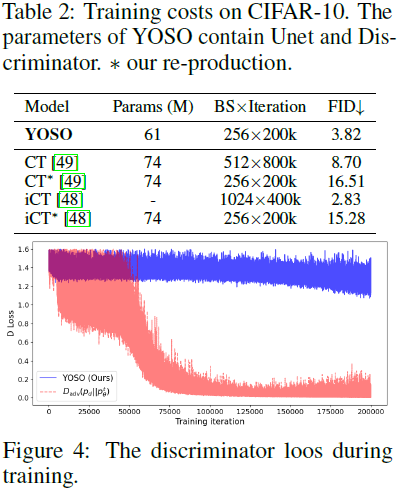
对抗散度 D_adv(p_d || p^t_θ)。 我们提出的 YOSO 的关键设计是通过使用自生成的(self-generated)数据而不是真实数据作为地面真实来平滑分布,从而执行对抗散度。 我们评估使用 D_adv(p_d || p^t_θ) 作为对抗散度的变体。 如表 1 所示,该变体的性能明显比 YOSO 差。 此外,除了样本质量之外,我们发现我们提出的 YOSO 的训练比变体稳定得多。如图 4 所示,该变体的判别器损失并不稳定,并且比我们的小得多。 这表明我们的方法可以有效地平滑分布,使假样本和真实样本的分布彼此更接近,从而使判别变得更加困难,而导致更高的判别器损失。